After several weeks of speculation
and leaked details, today Google officially unveiled its first big
foray into mobile payments in Asia. The Android and search giant has
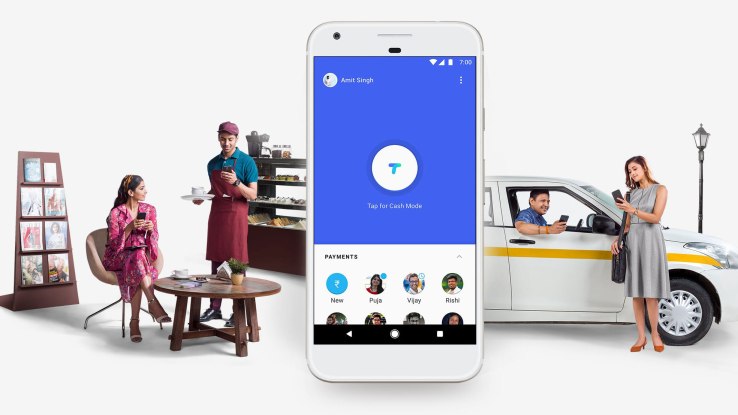
launched Tez,
a free mobile wallet in India that will let users link up their phones
to their bank accounts to pay for goods securely in physical stores and
online, and for person-to-person money transfers with a new twist: Audio QR, which uses ultrasonic sounds to let you exchange money, bypassing any need for NFC.
“Send money home to your family, split a dinner bill with friends, or
pay the neighbourhood chaiwala. Make all payments big or small,
directly from your bank account with Tez, Google’s new digital payment
app for India,” Google notes in its information portal about the new
app.Tez is Google’s play to replace cash transactions and become a more central part of how people pay for things, using their mobile to do so. But it’s also a chance for the company to push out some new technologies — like audio QR (AQR), which lets users transfer money by letting their phones speak to each other with sounds — to see how it can make that process more frictionless, and therefore more attractive to use than cash itself. More on AQR below.
Tez is launching today on iOS and Android in the country and will see Google linking up with several major banks in the country by way of UPI (Unified Payments Interface) — a payment standard and system backed by the government in its push to bring more integrated banking services into a very fragmented market. There will also be phones coming to the market from Lava, Micromax, Nokia and Panasonic with Tez preloaded, the company said.
Google has confirmed to us that payments made and taken using UPI are free for consumers and small merchants. “Google is not collecting any payments from transactions,” a spokesperson told TechCrunch. It is unclear how and if that will change when Google turns on functionality to upload cards to the Tez wallet, which is coming “in the next few weeks and months.” Card usage could come with a transaction fee.
To be clear, Tez is not a mobile “wallet” in the same way as PayTM offers a mobile wallet, where money is stored in the app and needs to be topped up to be used; it’s more like Apple’s Wallet or other mobile wallets in the west: a place that links up your phone with your bank accounts to let you use your phone as a way to deduct payments from those accounts.
Supported banks include Axis, HDFC Bank, ICICI and State Bank of India and others that support UPI. Online payment partners include large food chains like Dominos, transport services like RedBus, and Jet Airways. And tellingly, to help address one of the many ways that the Indian market is fragmented, the app has support for English, Hindi, Bengali, Gujarati, Kannada, Marathi, Tamil, and Telugu.
For money transfers, there is a limit of ₹1,00,000 in one day across all UPI apps, and 20 transfers in one day.
Google says that AQR — the sound-based format for transferring money securely between devices — is its own proprietary technology. This appears to be the first time that Google has used it for payments, although it has used ultrasonic sound for transferring information between devices before: for example, the tech has been used in Chromecast to connect devices since 2014. Other startups that have used audio-based “codes” to transfer payments and other data before include Lisnr, and Chirp.
While AQR might seem like a neat technical twist, there are some practical reasons behind why Google might opt for this in Tez. For starters, it obviates the need for NFC in the device, and in the payment devices of merchants or whoever else a person is planning to transact with. While we are seeing a greater proliferation of NFC and bluetooth across consumer electronics, it’s still not completely ubiquitous and when considering low-cost smartphones in countries like India, may not always be present.
The other thing is that it makes any kind of contactless transaction with the device fairly flexible and easy. Services like Airdrop on iPhones require Bluetooth and if you’ve used it before isn’t that seamless and foolproof to turn on (even though it works like a charm when it does). QR codes, meanwhile, require you to turn on the camera on your device and physically align it with a code on another screen, a potentially fiddly and difficult process. Using audio taps into some of the most basic features on even the most basic phones, a speaker and a microphone.
While the service is launching in India this week, Google has also trademarked the name in other Asian countries like Indonesia and the Philippines, so there seems to be a wider strategy to expand this to other regions.
India, the second-most populated country in Asia after China, is a ripe market for mobile payment services, with a rapidly expanding middle class with more disposable income and a wider population that is very tech-focussed, with an estimated 300 million smartphones in use today. Digital payments are expected to reach a volume of $500 billion annually by 2020, according to a report from BCG and Google.
At the same time, the market is challenging. India has to date had a very low credit card penetration, with many services based around cash payments. The general population has been resistant to changing those habits, and the regulatory framework up to now has not made it easier.
But as many know, using cash comes with its own price, so to speak. Users cannot build credit histories — which can be a problem when they need to make larger purchases or take out loans — and are cut out from buying certain things as a result. (Consider how many things today are, if not only, are certainly easier to buy with cards or online, like airplane tickets).
So times are now changing, and initiatives like UPI have led to the rise of newer services like Tez, with the government standing behind them. It was the Finance Ministry, in fact, that was responsible for one of the leaks ahead of today’s launch.
And in a sense, developing markets like India have even more potential for mobile-based payment services than more mature countries like the U.S., where there is already widespread use of cards for payments: there isn’t a useful and easy cash replacement service in use already that Tez is trying to disrupt. Tez, fittingly, is Hindi for “fast” — another pointer to how Google is pitching this as more convenient than what exists today.
There is also a separate business portal for online companies to integrate as sellers to accept Tez payments. This will not only let companies lay the groundwork to accept Tez payments for their goods and services in-store and on mobile, but comes with a larger merchant services backend: businesses get their on channels on the app to build potentially in place of their own apps, where they can create special offers, subscriptions, loyalty programs and other services to drive more sales.
We’re still asking Google more questions and will update the story as we get more information. For example, Google has confirmed to us that, initially, Tez will not work with enterprise accounts if you use them as your phone profile.
